当我们从几十个实验、模型或项目中挑出估值最高的一个,很容易把它当成真正的冠军。问题在于,每个估值都带着误差。胜出者不仅可能实力更强,也更可能碰巧拿到了较大的正误差。于是,方案未必选错,但我们对它值多少钱,常常估得太乐观。
这就是优化者诅咒(optimizer’s curse):在带噪声的候选估值中取最大值,选择过程会放大好看的随机波动。Erwann Rogard、Hao Lu 和 Andrew Gelman 在 2007 年发表的《Evaluation of multilevel decision trees》,研究了这个问题在多层决策树中的表现。本文关于该论文的事实和结论均来自 Andrew Gelman 2026 年的博客回顾,属于单一信源。
选冠军,也会选中噪声
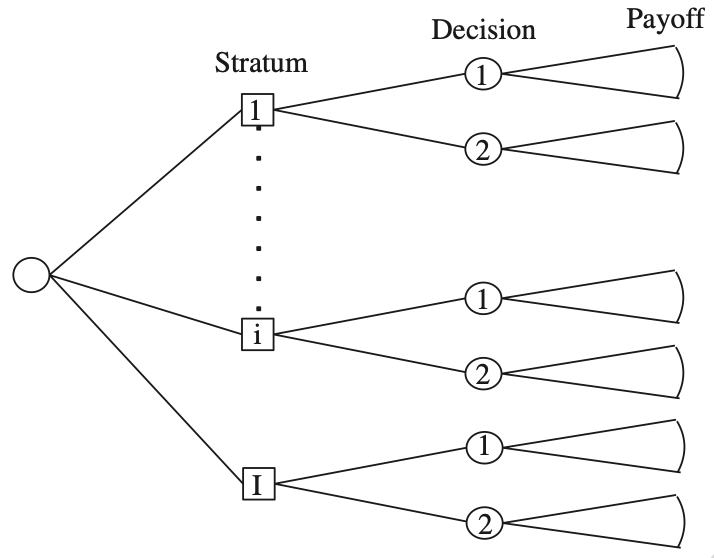
先看论文讨论的决策树。圆形节点代表不确定性,方形节点代表决策。人先进入某个未知的分层,也就是 stratum;进入后,要在两个选项之间做决定,而每个选项的收益同样不确定。
任务分成两层。局部上,要在每个分层里选出期望收益更高的方案。整体上,则要跨越所有分层取平均,评估整棵树在最优决策规则下的期望价值。
最自然的做法是:先估计每个选项的期望收益,选择较高者,再把这个较高的估计值拿去计算整棵树的价值。Gelman 转述论文结论称,这种估计存在系统性高估。
原因不难理解。两个方案的估值都有噪声,胜出的那个往往不只拥有较高的真实收益,也更可能拥有较有利的估计误差。继续用入选时的估值评价它,相当于既用一次成绩选冠军,又用同一次成绩证明冠军有多强。
这与回归均值相呼应:如果一次极端表现部分来自随机波动,重复测量时,它通常会更接近整体平均。选择后推断(post-selection inference)处理的正是这个问题——评估入选方案时,必须把“它因为表现最高才被选中”纳入不确定性分析。
诅咒不在决策,而在估价
这里有个容易误读的地方。“最优方案,可能只是运气最好”适合作为直觉,但不是说优化器总会选错,也不是说真实最佳方案完全由运气决定。
Gelman 明确区分了两件事:优化器根据现有信息选择看起来更好的方案,可能仍是合理决策;偏差发生在随后对净价值的评价上。若直接沿用经过筛选的高估值,判断就会过于乐观。
换句话说,优化者诅咒首先攻击的是“我们以为这次优化创造了多少价值”,而不是自动证明“这次优化做了坏决定”。这个边界很重要。否则,一个关于选择偏差的问题,很容易被扩写成对优化本身的否定。
为什么决策树更难算
纯粹的最大化容易合并:多个层级的最大值,最终仍可归为一次最大化。纯粹的平均也一样,平均的平均仍是平均。但不确定性决策树把 maximization 和 averaging 混在了一起。
在哪个分层中做什么选择,需要先最大化;整棵树值多少,又需要对不同分层和结果取平均。两种运算不能直接化简,只能沿着树的结构嵌套执行。
论文摘要指出,完整的嵌套评价通常需要较大的数据样本,或在模拟中投入较长计算时间。作者因此讨论了另一条路线:随机抽取一部分评价结果,再用统计方法推断整棵树。他们指出最自然的估计仍有偏差,并提出两种替代方案:parametric bootstrap(参数自助法)和 hierarchical Bayes inference(层级贝叶斯推断)。论文通过模拟研究考察了这些推断方法的性质,但博客未提供具体性能数字。
从背景概念看,收缩估计也提供了理解这类修正的入口:把噪声较大的单项估计适度拉回整体水平,避免把极端点估计原封不动地当成真实收益。它不是否认候选之间有差异,而是承认“看起来最高”本身已经提供了关于误差方向的信息。
为什么值得关注
这个问题横跨实验决策、模型选择和资源配置,因为它们共享同一种结构:先产生一批带噪估值,再选择最大的那个,最后还想用这些估值说明选择创造了多少收益。
候选越多,出现一个格外漂亮的估值并不奇怪。真正需要警惕的是,把筛选结果当成未经筛选的普通观测。优化过程已经改变了我们看到的数据分布,后续评价却常假装选择从未发生。
论文的价值不在于宣告“不要优化”,而在于把决策和评价拆开:可以依据当前信息行动,但评价行动价值时,需要校正选择带来的乐观偏差。对技术团队来说,这个区分很实用。一次胜出的实验结果,回答的是“按现有证据选谁”;它并不会自动给出“胜出方案真实领先多少”。
局限与未知
- 现有材料只转述论文摘要和作者回忆,没有披露模拟设定、样本规模、误差分布,也没有给出两种替代方案的效果数字,因此无法比较它们在何种条件下更可靠。
- Gelman 称论文在约 20 年间只被引用 3 次,但未说明所用数据库;而从 2007 年到 2026 年严格说约为 19 年。这个数字应视为未独立核查的作者说法。
- 材料能支持的是:朴素地复用入选方案的估值,会高估决策树的净价值。它不能支持“优化总会选错”,也不能证明实际最佳方案只是运气最好。